
Rethinking SIEM
Newsletter Issue #180: Rethinking How We Do SIEM

Having logs can save you in an investigation or an incident, and the SIEM is where we have done this.
Historically, there’s been a notion in Security that more data is better, or “logging all the things” is the way to go.
The idea that you should ingest logs you’ve never actually used, in the event you might ever need them.
This sort of portrays a scarcity mindset, possibly due to the fact that when the security team is called, this means it’s probably going to be a bad day.
Many incidents lead to a plethora of log analysis, and finding the right data can be a challenge.
Compound this over the years, and you have the common belief that more data is better.
Here are a few blog posts on why this is usually a bad idea.
Cost perspective

Different Goals
Why there won’t be a convergence of security and observability pipelines any time soon
In a nutshell, you shouldn’t default to logging everything as a blanket statement regardless of use case.
Now let’s take state.
How Did We Get Here?
Let’s take a step back to take in how we got here as an industry.
First, as a Security team you need data.
You know that having logs in a security investigation is good. So you set up an ingest pipeline for audit logs, SSO logs, maybe EDR logs.
Then you add your SaaS Application logs.
After awhile, the SRE team hears about this cool logging platform you got going on, and says they want some of their health metrics pushed into the SIEM.
Then another team wants to put in their application logs, then another team (this team ends up logging in once a month at best)
Before you know it, your ingest is not what you signed up for. And you have a problem.
Couple this with the de-facto pricing model of charging by raw volume, and you’re in a hole.
So all of the additional data sources that seem like a good idea to log? They add up in cost. The Vendor is hoping you have growth, as this means more $$ for them.
So where does that leave us?
This has been going in mainly two ways.
With the problem of log ingestion being too expensive at modern scale, or the unbundling of the centralized logging platform as we knew it.
Where you either prioritize your log sources, and the data that you choose to ingest vs filter out, or you utilize different logging platforms for different use cases (SIEM vs Data Lake vs Data Warehouse vs Cloud Cold Storage). You get the idea.
You can argue whether this use case dependent decoupling is good or bad.
Is there a better approach?
Let’s get into it.
Let’s go over some approaches to your security logging strategy.
I will be using the following terms in these approaches.
Data processor
This could be a normalization pipeline (CEF, OCSF, etc.), a parser with a collection of plugins, a vendor solution that filters out certain events from making it to your SIEM (or enriches events), or a home grown tool that then pipes events to your logging platform.
Put simply, this sits between your origin of data and your SIEM.
Cloud Storage
This is to say a long(er) term location for your logs, where you could still query them if you need to. However, the main focus is still storage here. This could then go to cold storage for more cost savings.
With terms out of the way, let’s go over a couple approaches that turn traditional SIEM logging on its head.
First Design Approach
Data Source → Data processor → Detection Logic Here → Cloud Storage → SIEM (Detections only)
This effectively turns your data processor as your living space for detection logic, your Cloud storage as your (more affordable) queryable storage, and your SIEM as your output of that logic.
This shifts the way we have viewed SIEM at a fundamental level.
In practice think something like an index=detection_rules
You could have a world where you effectively use your SIEM as your detection space, but for little else.
Second Design Approach
In another approach, you can have a pipeline where you have your data processor doing some heavy lifting, and you utilize your cloud storage for ad-hoc querying/hunting.
Your SIEM gets the heavily filtered data, and is a first source for low hanging fruit, with your cloud storage as your fallback if you need more data.
This follows a lot of the logic for the first approach, but with the difference of still using the SIEM for some hunting (vs detections only).
This could look like the following.
Data Source → Data processor → Queryable Cloud Storage → SIEM gets filtered data only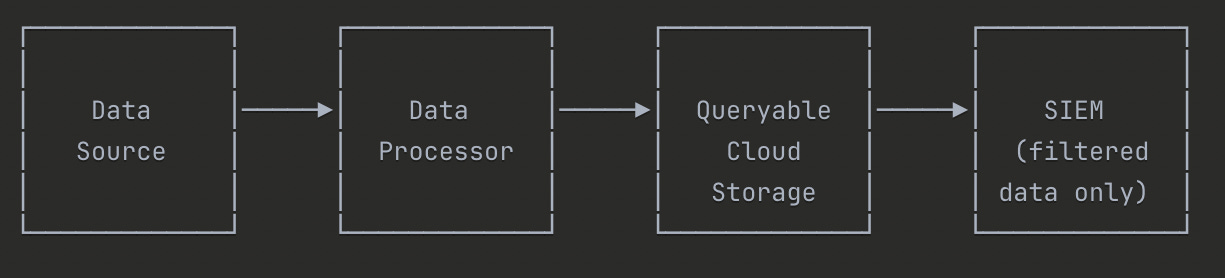
You start with the data in your point of origin like everyone else. This could be Okta System logs, EDR logs, or local auth.log log files.
They then go through parsing/filtering through some kind of data processor, the details here will vary depending on your goal.
From here, they go to a place of storage that could be queried if needed (think Athena querying from S3, BigQuery from Google Cloud Storage, Synapse from Blob storage, etc.)
These logs then go through your detection lifecycle in your SIEM or they land in your SIEM as detection rules as described in the first approach.
In another stream, the logs are going through more heavy filtering, only keeping what is relevant for a security investigation.
I mean it’s in the name, Security Information and Event Management. We have to ask ourselves, why would we put data that won’t be used for security purposes in a SIEM?
There are options for many vendor tools or open source tools here for the above approaches.
Brian Davis went over some ideas for this in his talk at SANS CloudSec Summit.

This touches on the topic of bifurcation, where there is SIEM and there is Observability. Each with its own main use cases, and that’s okay.
What we really need is quality systems that allow you to query data whenever needed. Being able to hunt on this data is a requirement, where having it all in one centralized location is not a hard requirement.
What could this mean for the industry?
Not being tied to logging all your data to the SIEM.
I never agreed with the concept of “logging all the things”, and if I had to sum it up here are a few reasons for this.
It’s expensive
You usually don’t need EVERYTHING in your SIEM
You end up being drowned out in noise when you need the logs
The Counter Argument
I remember an instructor at a security training once saying “I never once have been working late on an incident, thinking I wish I had less logs, but I have said before I wish I had more logs” .
This may seem right.
Another way of saying this is having the right logs.
For example, if an incident is solely revolving around one application, then application logs for this are needed for root cause. If this is an infected laptop, then host based EDR logs are in order.
But even here, there is nuance. Let’s say you’re in a Google Workspace shop and you’re onboarding Google Workspace into your SIEM.
Unless your threat model is a highly targeted company, you could probably get away with not bringing in full Calendar logs, or Meet logs to your SIEM. Audit logs, Email, or Drive logs will be a lot more valuable for detections and in investigations. The rest can go in another form of storage (see above design approaches)
Using the right tool for the job, or in this case, the right trail for the job is key. You wouldn’t bring your whole toolbox to change a tire would you?
If your team (or you) is drowning in data when it comes time to run an investigation, you might be having second thoughts on your log ingestion approach.
Unless you enjoy data wrangling as your main job or you’re running a lot of automation (a lot), it just doesn’t make a lot of sense for most to be ingesting all their data that comes down the pike.
Another counter could be the notion that Security hasn’t always been an engineering shop, and home grown solutions have not been common. With Silicon Valley being the exception.
For years, it was commonplace for security teams to be more “ops” focused, putting out fires or being the administrators of purchased tools, and not having someone who was a builder on the team.
Why build when you can buy? Someone might say.
I think the rest of the industry has realized the benefits, and sometimes the need to DIY for security tooling. Custom use cases, full control over the bits, and no vendor lock in just to name a few. Sometimes a vendor solution is the best for your stack. Sometimes it’s not.
The question behind the question becomes “is the juice worth the squeeze?”
Ultimately, deciding the design approach you go with comes down to the data and its value to your team.
What I Read This Week
Building AI for cyber defenders
Evaluations showed Sonnet 4.5 beating their flagship model Opus 4.1 at finding and fixing vulnerabilities as well as improved performance in CTF challenges
Some of these challenges involved analyzing network traffic, extracting malware from that traffic, and decompiling and decrypting the malware
DPRK IT Workers: Inside North Korea’s Crypto Laundering Network
A good deep dive on the inner working of a money laundering operation
In a nutshell the flow is: Get paid in stablecoins -> token swapping -> commingle through wallet addresses -> main exchanges (verified with fraudulent id)
Good Staff Engineers / Bad Staff Engineers
A good overview on the differences between the two. An excerpt: good Staff Engineers “level up everyone around them” and “take ownership over misses”
Good eye-opener for the performative folks out there
Books for Cybersecurity Awareness Month
It’s that time of the year. Some really timeless reads in the list here

Breaches
Discord discloses data breach after hackers steal support tickets
Information impacted included: names, usernames, email addresses, IP, and photos of government-issued ID (if provided)
This raises the question of uploading your government ID for age-verification purposes. Is there a better way?
ParkMobile pays... $1 each for 2021 data breach that hit 22 million
This stems from a 2021 breach that involved the company user data being compromised, resulting in a class action lawsuit

Here’s a dollar? They’re also going to make you work for it

From above linked Bleeping Computer post Unbelievable what these companies are pulling off
Security update: Incident related to Red Hat Consulting GitLab instance
Red Hat confirmed that the incident was a breach of its GitLab instance used for Red Hat Consulting on engagements
Companies whose data was impacted include: Bank of America, AT&T, Kaiser, Mayo Clinic, Walmart, Costco, T-Mobile
Update as of 10/7: Crimson Collective and ShinyHunters have launched a leak site, threatening to release 570GB of the stolen data


Wrapping Up
In this post, we discussed the idea of rethinking your SIEM strategy and that “more logs” is not always better. I am optimistic the Detection space is seeing this and we will have a reshaping of this field.
Newsletter post #180 is in the books.
See you in the next one.